About
I am a third year Computer Science Ph.D. student at Rochester Institute of Technology (RIT), New York. I am advised by Dr. Xumin Liu and I collaborate with the Machine Learning and Data Intensive Computing Lab led by Dr. Qi Yu.
My research explores Adversarial Robustness, Continual Learning, and Data-Efficient Deep Learning. The models I work with are primarily based on Vision Transformers, Vision Language Models, Large Language Models, and CNNs.
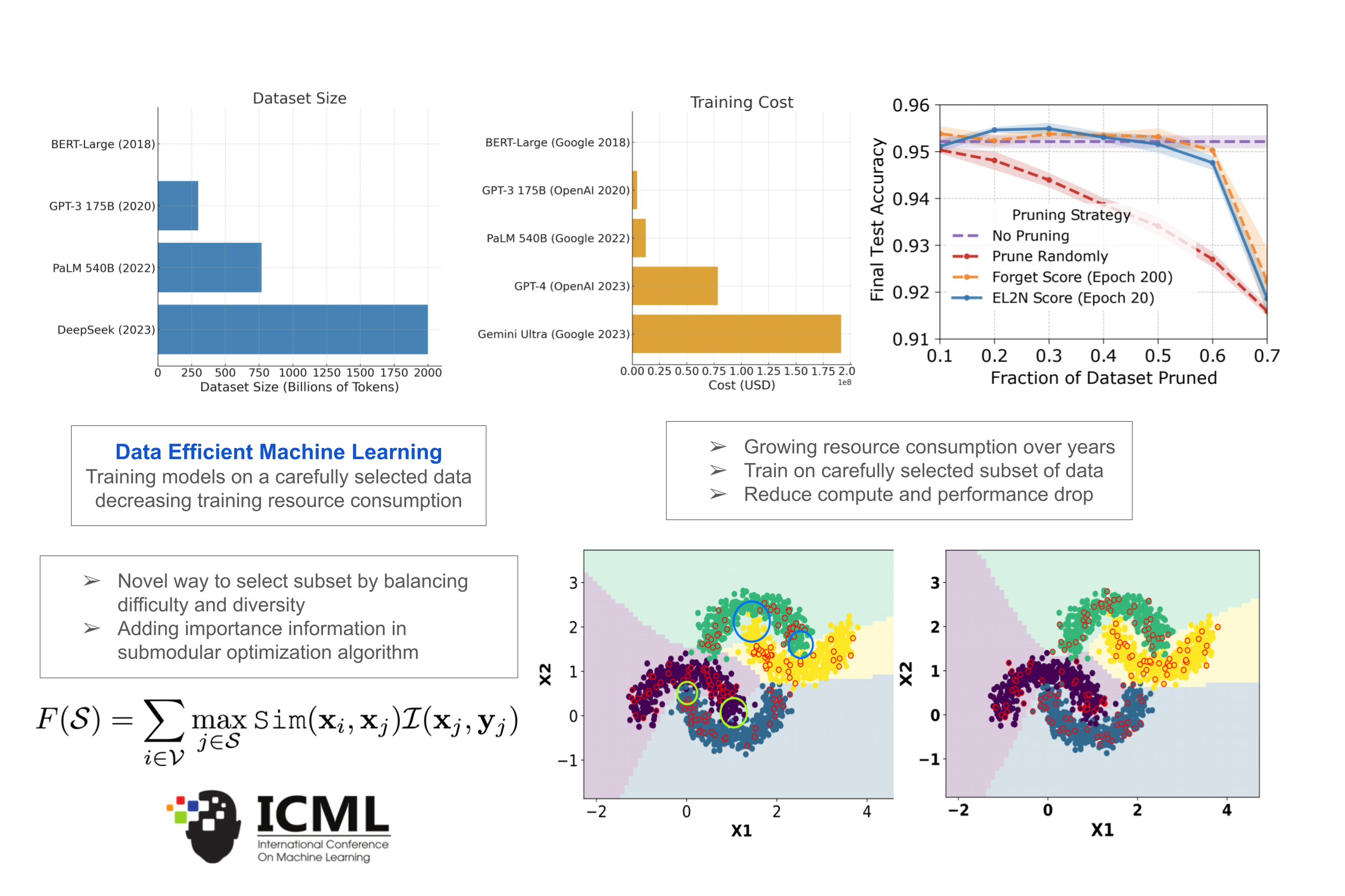
Data Efficient Machine Learning
The success of deep learning comes at the cost of large amounts of data and increased resource consumption Subset or coreset selection aims to find candidate data points from a large pool of data such that the model trained on the subset has comparable performance to that of the model trained on thefull set, which in turn helps decrease the resources consumed by training on large amounts of data. Paper
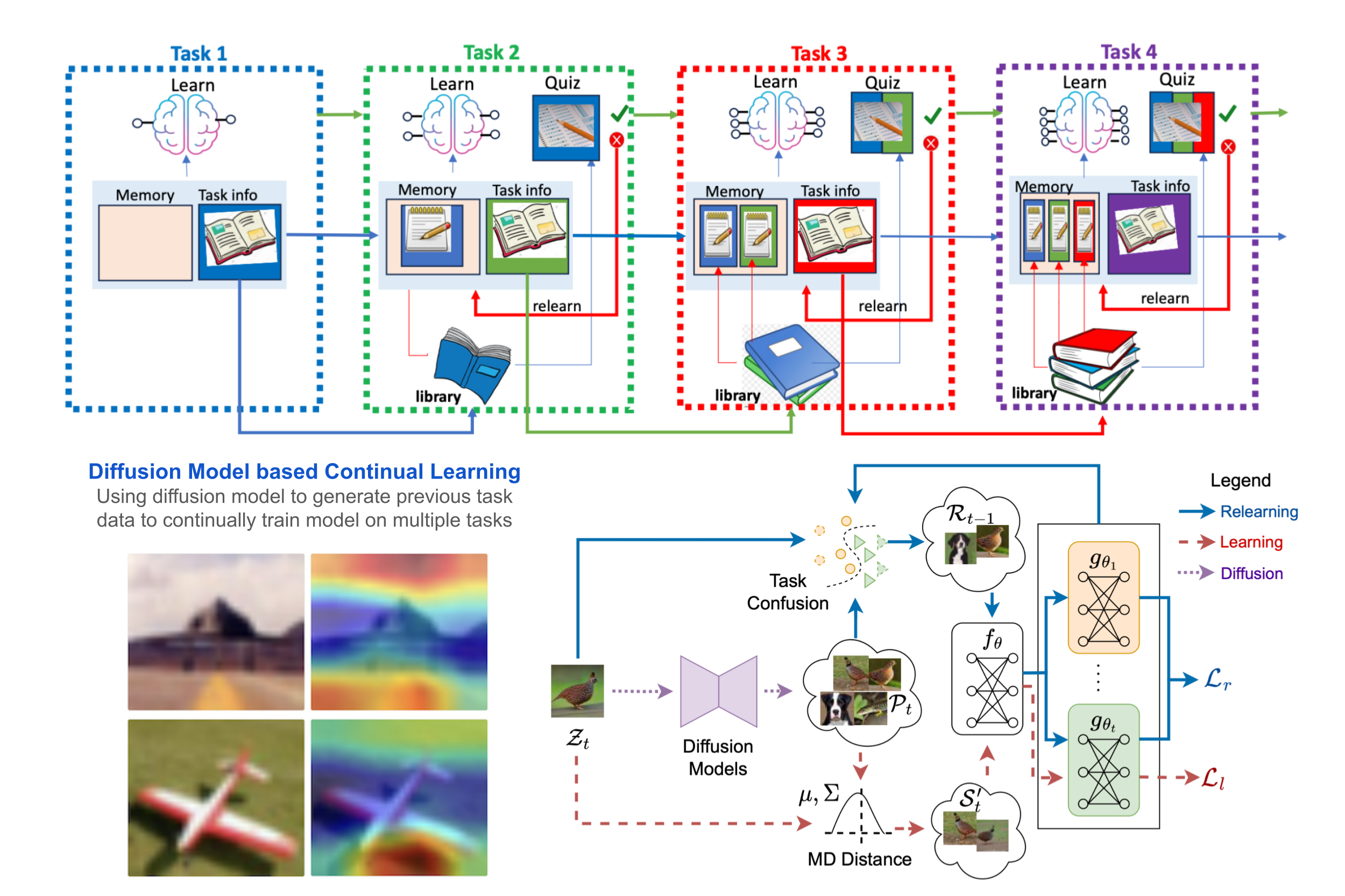
Diffusion Model Based Continual Learning
Continual learning models can learn new tasks over time while trying to maintain what they have learned before. Inspired by how humans revisit past knowledge, we introduce a new relearning method that uses generative replay to measure how much information is lost after learning a new task. We then realign the model by retraining it for a few epochs on a selected subset of library samples that the model finds confusing across tasks, essentially performing a targeted generative relearning step. Paper
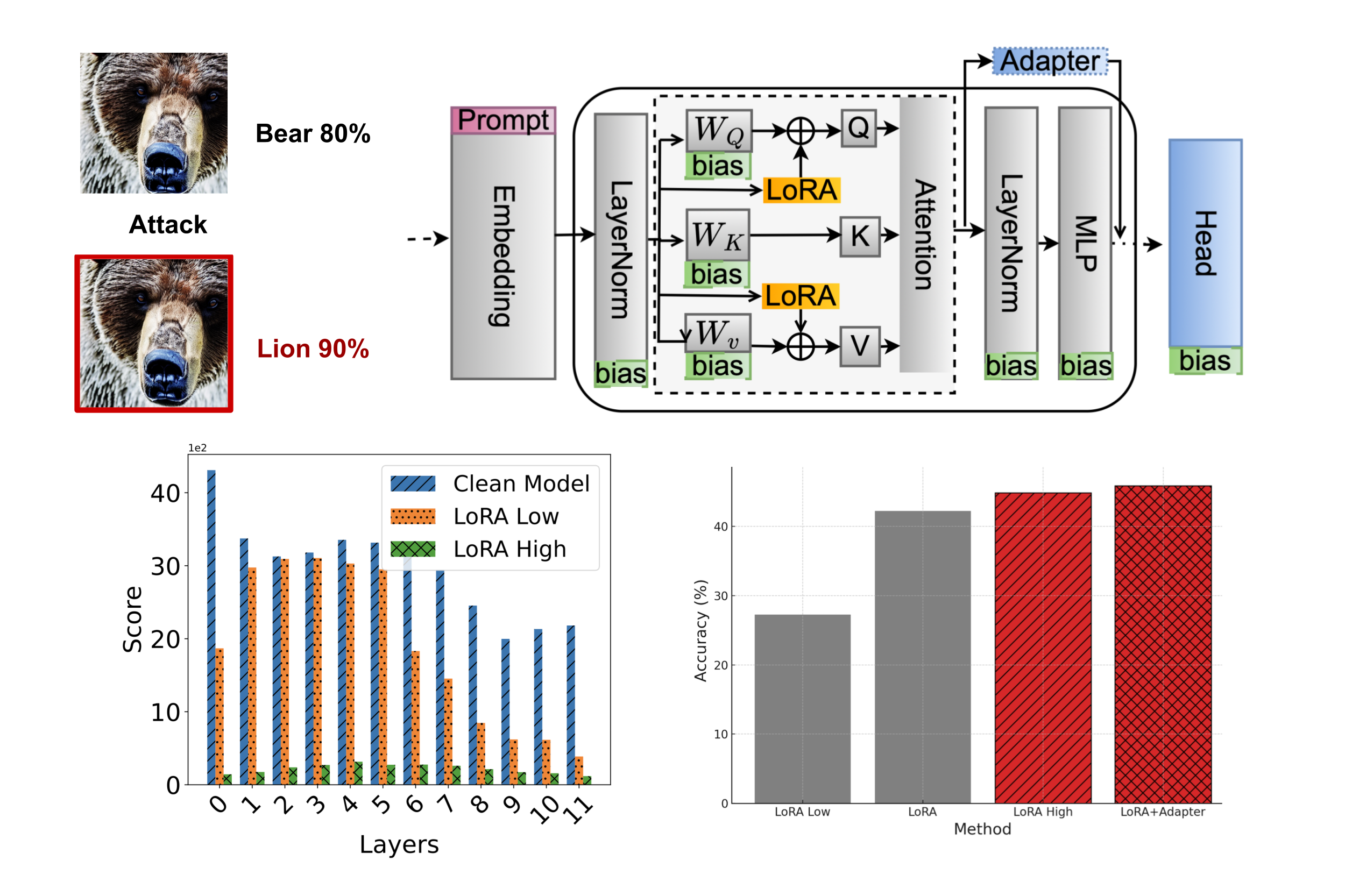
Parameter Efficient Robust Fine-tuning
Adversarial robustness in ViTs can be improved by recognizing that not all layers are equally vulnerable to attacks. Instead of uniformly adapting the model, we focus on parameter-efficient finetuning (PEFT) that identifies and reinforces these vulnerable layers. By selectively allocating more parameters to the layers that contribute most to adversarial weakness, our layer-aware PEFT strategy strengthens the model’s defenses while remaining efficient. Paper
Application of my Research in Industry
In real-world industry environments, machine learning models are rarely built from scratch every time. More often than not, there’s already a model running in production. That model was trained on some initial old dataset. But as time passes, things change: the data evolves, and user needs shift. The availablity of new data naturally raises important questions about how the new data should be used:
- Should we combine the new data with the old and retrain the model from scratch?
- Should we ignore the old data and train a completely new model with new data?
- Is it better to initialize with the current model’s weights and continue training?
- Or, should we quickly build a prototype to see if the model even works on the new data?
How to train the model depend on several real-world constraints:
- Do we have the storage to retain all previously collected data?
- How much time, compute, and energy will full-retraining require? Can we justify the cost? Can we afford the cost?
- Can we afford to run hyperparameter tuning again?
- What if we spend all those resources on retraining, only to find out the model performs worse?
If you’ve encountered questions like these, you’re not alone, this is exactly where my research becomes valuable. Here are some cost-effective strategies that directly stems from my research:
- Selective Training: Carefully choose a subset of both old and new data for training, instead of using everything.
- Continual Learning: Continue training from the existing model — even when the original training data is no longer accessible.
- Efficient Tuning: Perform hyperparameter tuning on just the selected subset, rather than the full dataset.
Of course, how to select the data depends on your specific goals:
- Do you need maximum performance?
- Is your priority to minimize resource usage?
- Is the old data distribution more important than maintaining accuracy on the new one?
These trade-offs are at the heart of what I explore in my research, helping organizations adapt to change, without starting from zero.